




PostgreSQL���g���v�� - ��29�v������Ӌ���c�ɱ�����
���WӍ������OCP�J�C���ڈ����У���ԇ�ˆT�^��Ո�M������@ȡ�����ԇ�r�g�������M��Ոϵ�ھ��ώ������Ĺٷ��J�C���������٣�
��Ҫ��ԃ
PostgreSQL��С�����ң��Ǐ����T��u����������һ��ϵ�н̳̣����ݰ�����PG���A���J֪���������bʹ�á�������ɫ���ޡ������S�o���������ȃ��ݣ�ϣ�������PG���W��PG��ͬ�W���Ў������gӭ���m�PעCUUG PG���g���v�á�
��29�v������Ӌ���c�ɱ�����
����1 : PostgreSQL�в�ԃ��������
����2 : ȫ�����ɱ�����
����3 : ��������ɱ�����
����
�� SQL�Z������岽�E

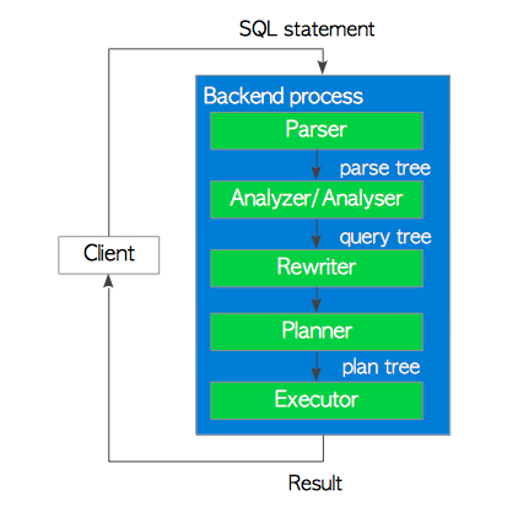
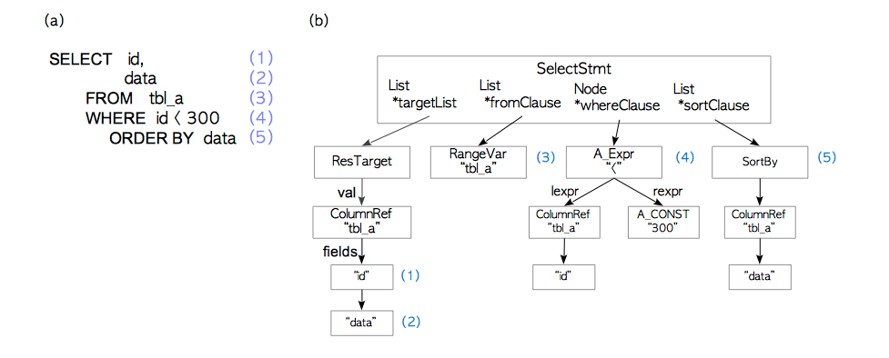
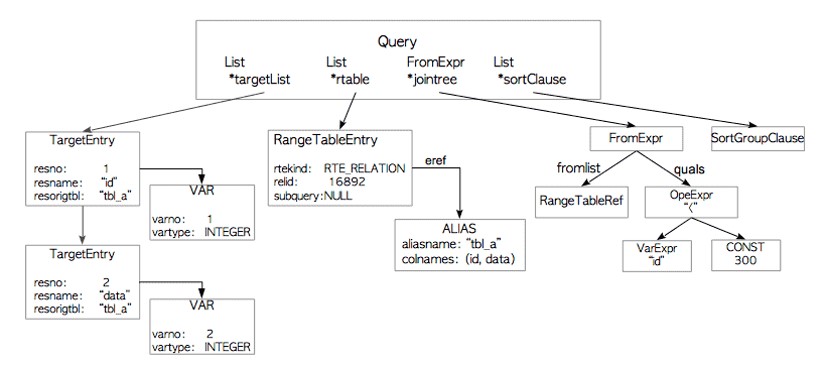
Parser
����������һ�������䣬���m��ϵ�y���ԏļ��ı���SQL�Z�����xȡԓ�䡣
Analyzer/Analyser
������/�����������ɵĽ������\���Z�x�����������ɲ�ԃ�䡣
Rewriter
�،����nj��FҎ�tϵ�y��ϵ�y����Ҫ�r����pg_rulesϵ�yĿ��д惦��Ҏ�t�D�Q��ԃ�䡣
PostgreSQL�е�ҕ�D��ͨ�^Ҏ�tϵ�y���F�ġ�ͨ�^������ҕ�D������xҕ�D�r�����Ԅ�����������Ҏ�t������惦��Ŀ��С�
���O�ѽ����x������ҕ�D����������Ҏ�t�惦��pg_rulesϵ�yĿ��С�
CREATE VIEW employees_list
AS SELECT e.id, e.name, d.name AS department
FROM employees AS e, departments AS d
WHERE e.department_id = d.id;
Planner and Executor
Ҏ�������،������ղ�ԃ�䣬�����ɣ���ԃ��Ӌ���䣬�����߿�������Ч��̎��ԓ�䡣
pg_hint_plan���
PostgreSQL��֧��SQL�е�Ӌ������ʾ���������h����֧���������Ҫ�ڲ�ԃ��ʹ����ʾ����Ҫ����pg_hint_plan�Uչ�����
����Ӌ��
�� Explain�@ʾsql����Ӌ��
�c����RDBMSһ�ӣ�PostgreSQL�е�explan�����@ʾӋ���䱾����
���磺
testdb=# EXPLAIN SELECT * FROM tbl_a WHERE id < 300 ORDER BY data;
QUERY PLAN
---------------------------------------------------------------
Sort (cost=182.34..183.09 rows=300 width=8)
Sort Key: data
-> Seq Scan on tbl_a (cost=0.00..170.00 rows=300 width=8)
Filter: (id < 300)
(4 rows)
�������c���_�^�Pϵ
�����������_�^���������R�r�ļ�֮�g���Pϵ
�α���ԃ�ɱ�����
�� �α���ԃ�еijɱ�����
�������ڳɱ����ɱ��ǟo���Vֵ���@Щ���ǽ^���Ŀ�Чָ�ˣ����DZ��^�\�I������Ч��ָ�ˡ�
�����߈��е����в��������������ijɱ�������
���N�ɱ������ӡ��\�кͿ�Ӌ�����ɱ��dž��Ӻ��\�гɱ��Ŀ���
���ӳɱ����ګ@ȡ��һ����֮ǰ���M�ijɱ������磬�������蹝�c�Ć��ӳɱ����xȡ����������L��Ŀ�˱��еĵ�һ��Ԫ�M�ijɱ���
�\�гɱ��ǫ@ȡ�����еijɱ���
���ɱ��dž��Ӻ��\�гɱ��ijɱ�֮�͡�
�� �α���ԃ�еijɱ�����
EXPLAN�����@ʾÿ�������еĆ��ӺͿ��ɱ�����ε�����������ʾ��
testdb=# EXPLAIN SELECT * FROM tbl;
QUERY PLAN
---------------------------------------------------------
Seq Scan on tbl (cost=0.00..145.00 rows=10000 width=8)
�ڵ�4���У������@ʾ���P���������Ϣ���ڡ��ɱ��������У��Ѓɂ�ֵ��0.00��145.00�����@�N��r�£����ӺͿ��ɱ��քe��0.00��145.00��
�α���ԃ�ɱ�����֮������
�� Sequential Scan�ɱ�Ӌ��
������ijɱ���cost_seqscan�����������㡣�҂���̽ӑ��ι������²�ԃ��������ɱ���
testdb=# SELECT * FROM tbl WHERE id < 8000;
���������У����ӳɱ�����0���\�гɱ������µ�ʽ���x��
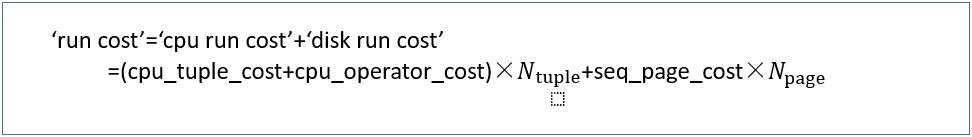
�� Sequential Scan�ɱ�Ӌ��
��ԃ���ĉK����page�����Д���tuple����

������1��2���ó�
��run cost��=(0.01+0.0025)��10000+1.0��45=170.0
���ɱ���
��total cost��=0.0+170.0=170
�� Index Scan�ɱ�����
Ӌ������IJ�ԃ�Z��ͨ�^�����L���ɱ�Ӌ�㣺
testdb=# SELECT id, data FROM tbl WHERE data < 240;
�Ȳ�ԃ�������Д���퓔�N_(index,tuple) N_(index,page)

�� IndexScan �ɱ�����
���ӳɱ�Ӌ�㹫ʽ
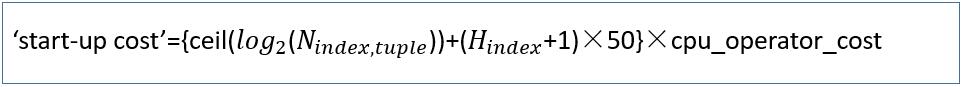
H_indexָ���������ĸ߶�
���ӳɱ�Ӌ��Y����

�� IndexScan�ɱ�����
�\�гɱ�Ӌ�㹫ʽ
����������\�гɱ��DZ���������cpu�ɱ���IO��ݔ��/ݔ�����ɱ�֮��
��run cost��=(��index cpu cost��+��table cpu cost��)+(��index IO cost��+��table IO cost��)
ǰ�����ɱ���������cpu�ɱ�����cpu�ɱ�������IO�ɱ���Ӌ�㹫ʽ��

�� Selectivity
����ÿһ�е�MCV(Most Common Value)����һ��most_common_vals��most_common_freqs���д惦��pg_statsҕ�D�С�
most_common_vals���Ҋ�ĵ�ֵ���ǽyӋMCVs�б����С�
most_common_freqs���Ҋֵ���l�ʣ��ǽyӋmcv���l���С�
mydb=# \x
Expanded display is on.
mydb=# SELECT most_common_vals, most_common_freqs
FROM pg_stats
WHERE tablename = 'countries' AND attname='continent';
-[ RECORD 1 ]-----+---------------------------------------------------------------------
most_common_vals | {Africa,Europe,Asia,"North America",Oceania,"South America"}
most_common_freqs | {0.2746114,0.24352331,0.22797927,0.119170986,0.07253886,0.062176164}
�� Selectivity
�҂����]����IJ�ԃ������һ��WHERE�Ӿ䣬��contain=��Asia'��
testdb=# SELECT * FROM countries WHERE
continent = 'Asia';
SELECT continent, count(*) AS "number of countries",
(count(*)/(SELECT count(*) FROM countries)::real) AS "number of countries / all countries"
FROM countries GROUP BY continent ORDER BY "number of countries" DESC;
continent | number of countries | number of countries / all countries
---------------+---------------------+-------------------------------------
Africa | 53 | 0.27461139896373055
Europe | 47 | 0.24352331606217617
Asia | 44 | 0.22797927461139897
North America | 23 | 0.11917098445595854
Oceania | 14 | 0.07253886010362694
South America | 12 | 0.06217616580310881
�� Selectivity
���Y��
�c�����ޡ��������Ҋ�l��ֵ��0.227979����ˣ���ԓ��Ӌ��ʹ��0.227979�����x���ԡ�
������ֵ���x헺ܸߵ���r���Ͳ���ʹ��MCV���tʹ��Ŀ���е�ֱ���D����ֵ����Ӌ�ɱ���
�� histogram_bounds
��һ��ֵ�б������ڌ��е�ֵ�ֳɴ�����ȵĿ��w�M
�� Buckets and histogram_bounds

testdb=# SELECT histogram_bounds
FROM pg_stats
WHERE tablename = 'tbl' AND attname = 'data';
Ĭ�J��r�£�ֱ���D���ޱ����֞�100��Ͱ�������ԃ�f�����@�������е�Ͱ��������ֱ���D������bucket��0�_ʼ��̖��ÿ��bucket�惦����s����ͬ������Ԫ�M��ֱ���D����ֵ�������惦Ͱ�Ľ��ޡ����磬ֱ���D�Ͻ�ĵ�0��ֵ��1���@��ζ�����Ǵ惦��bucket_0�е�Ԫ�M����Сֵ����1��ֵ��100���@�Ǵ惦��bucket_1�е�Ԫ�M����Сֵ��������ơ�
�� Selectivity
WHERE data<240Ӌ���x����
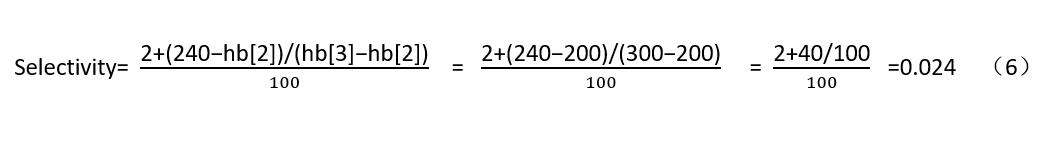
�� IndexScan�ɱ�����
ǰ�����ɱ���������cpu�ɱ�����cpu�ɱ�������IO�ɱ���Ӌ�㹫ʽ��

������1��3��4��6������cpu�ɱ�����cpu�ɱ�������IO�ɱ�Ӌ��Y����
��index cpu cost��=0.024��10000��(0.005+0.0025)=1.8, ��7��
��table cpu cost��=0.024��10000��0.01=2.4, ��8��
��index IO cost��=ceil(0.024��30)��4.0=4.0. ��9��
�� IndexScan�ɱ�����
table IO costӋ�㹫ʽ��

�� IndexScan�ɱ�����
max_IO_costӋ�㹫ʽ�c�Y����

min_IO_costӋ�㹫ʽ�c�Y����

�� indexCorrelation
indexCorrelation=1.0 ��12��
������10��11��12����
��table IO cost��=180.0+��1.0��^2��(5.0?180.0)=5.0 ��13��
������7��8��9��13���ó������L�����ɱ���
��run cost��=(1.8+2.4)+(4.0+5.0)=13.2 ��14��
�� �е�indexCorrelation��ԃ
testdb=# \d tbl_corr
Table "public.tbl_corr"
Column | Type | Modifiers
----------+---------+-----------
col | text |
col_asc | integer |
col_desc | integer |
col_rand | integer |
data | text |
Indexes:
"tbl_corr_asc_idx" btree (col_asc)
"tbl_corr_desc_idx" btree (col_desc)
"tbl_corr_rand_idx" btree (col_rand)
testdb=# select * from tbl_corr;
col | col_asc | col_desc | col_rand | data
----------+---------+----------+----------+------
Tuple_1 | 1 | 12 | 3 |
Tuple_2 | 2 | 11 | 8 |
Tuple_3 | 3 | 10 | 5 |
Tuple_4 | 4 | 9 | 9 |
Tuple_5 | 5 | 8 | 7 |
Tuple_6 | 6 | 7 | 2 |
Tuple_7 | 7 | 6 | 10 |
Tuple_8 | 8 | 5 | 11 |
Tuple_9 | 9 | 4 | 4 |
Tuple_10 | 10 | 3 | 1 |
Tuple_11 | 11 | 2 | 12 |
Tuple_12 | 12 | 1 | 6 |
(12 rows)
�� indexCorrelation�c��֮�g���Pϵ
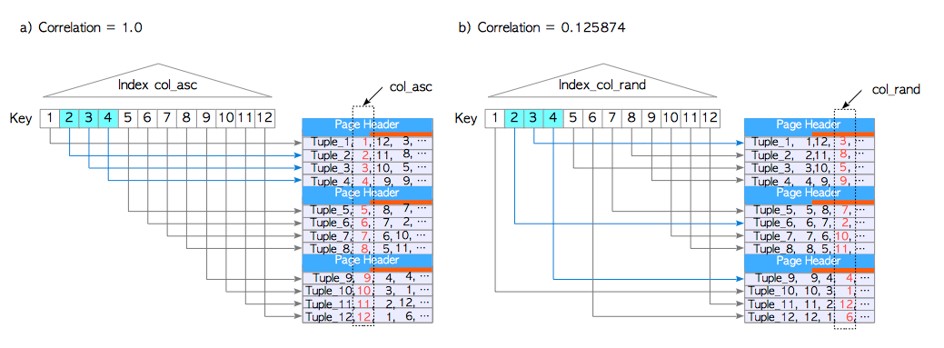
�� �е�indexCorrelation��ԃ
testdb=# SELECT tablename,attname, correlation FROM pg_stats
WHERE tablename = 'tbl_corr';
tablename | attname | correlation
-----------+----------+-------------
tbl_corr | col_asc | 1
tbl_corr | col_desc | -1
tbl_corr | col_rand | 0.125874
�� ���ɱ�
������5��14�����ó�ͨ�^�����L�����Ŀ����r��
��5��--���ӳɱ�
��14��--ͨ�^�����L�����ijɱ�
��total cost��=0.285+13.2=13.485 ��15��
testdb=# EXPLAIN SELECT id, data FROM tbl WHERE data < 240;
QUERY PLAN
---------------------------------------------------------------------------
Index Scan using tbl_data_idx on tbl (cost=0.29..13.49 rows=240 width=8)
Index Cond: (data < 240)
�� seq_page_cost and random_page_cost���P��������
HDDӲ�P��
seq_page_cost=1.0
random_page_cost=4.0
SSDӲ�P��
seq_page_cost=1.0
random_page_cost=1.0
�α���ԃ�ɱ�����֮����
�� Sort
�ɱ����㹫ʽ��

�������²�ԃ�Z������ɱ���
testdb=# SELECT id, data FROM tbl WHERE data < 240 ORDER BY id;
�� Sort�ɱ�����

-->> ���ڹ��_�n�Y�ϣ�ϵCUUG�ͷ��Iȡ
���Ͼ��ǡ�PostgreSQL��С�����ҡ���29�v -����Ӌ���c�ɱ����� �ă��ݣ��gӭ�MȺһ��̽ӑ����
�ᔽ���Ⱥ��35822460����Ⱥ���T��ҕ�l�v��

PostgreSQL���T����ͨ 100+ ���W���Y��

- Ƚ�˾V-�ώ�CUUG�����v��
- Ƚ�ώ� CUUG�����v�� Oracle��RedHat���v����Unix/Linux �Y���...[Ԕ���˽��ώ�]

- ��l��-�ώ�CUUG�����v��
- ��ώ� CUUG�����v�� ��ͨOracle��������ݻ֏͡����܃��� 11��Ora...[Ԕ���˽��ώ�]






